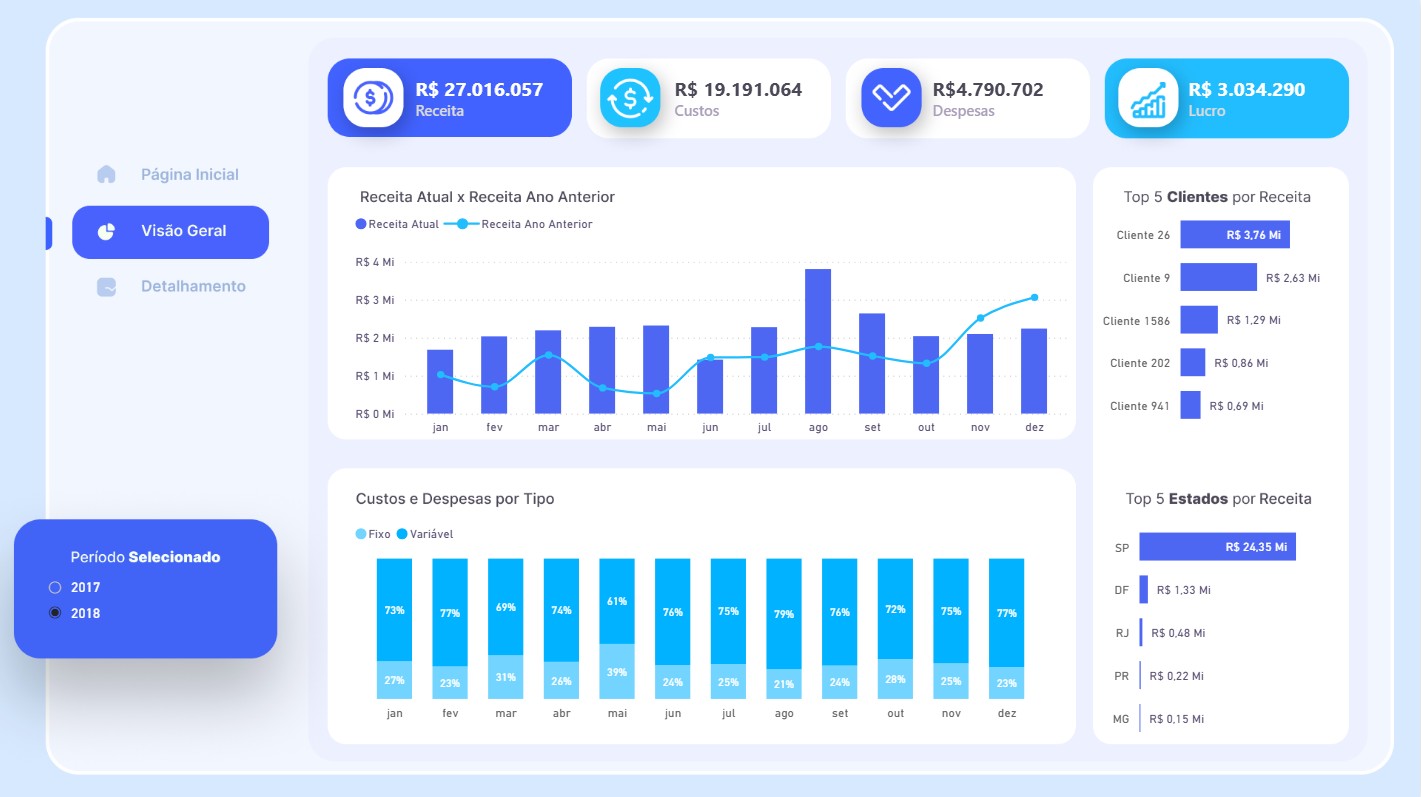
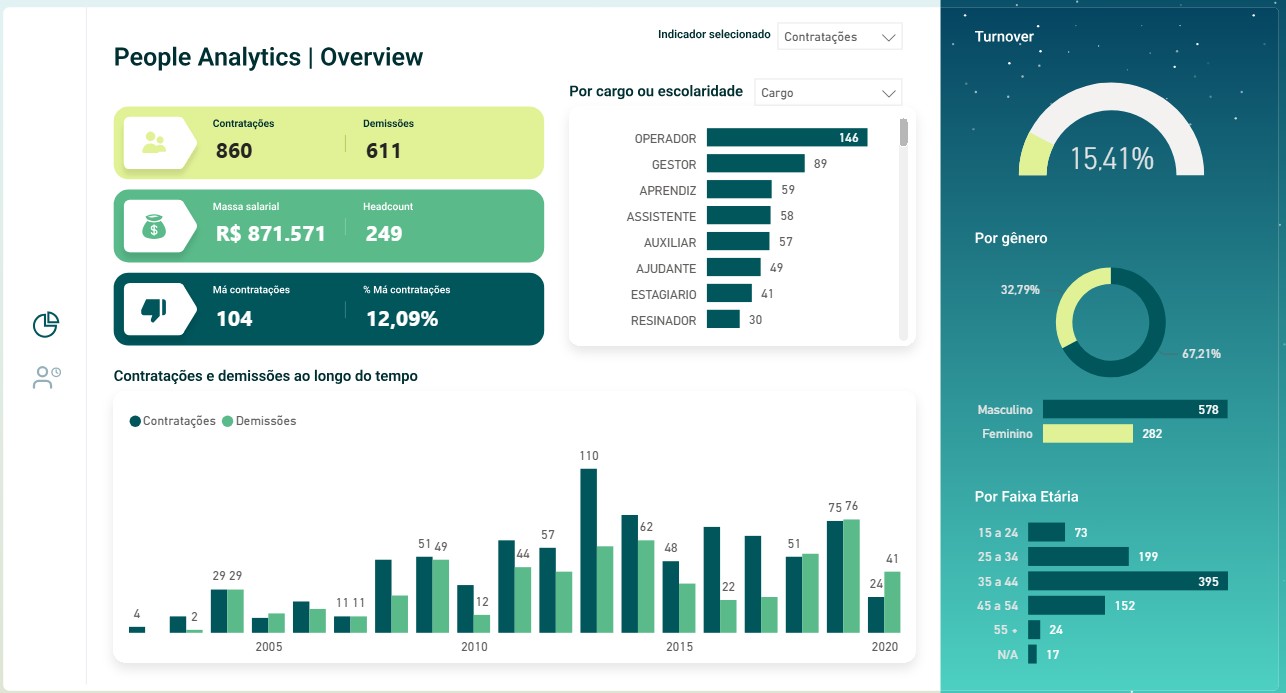
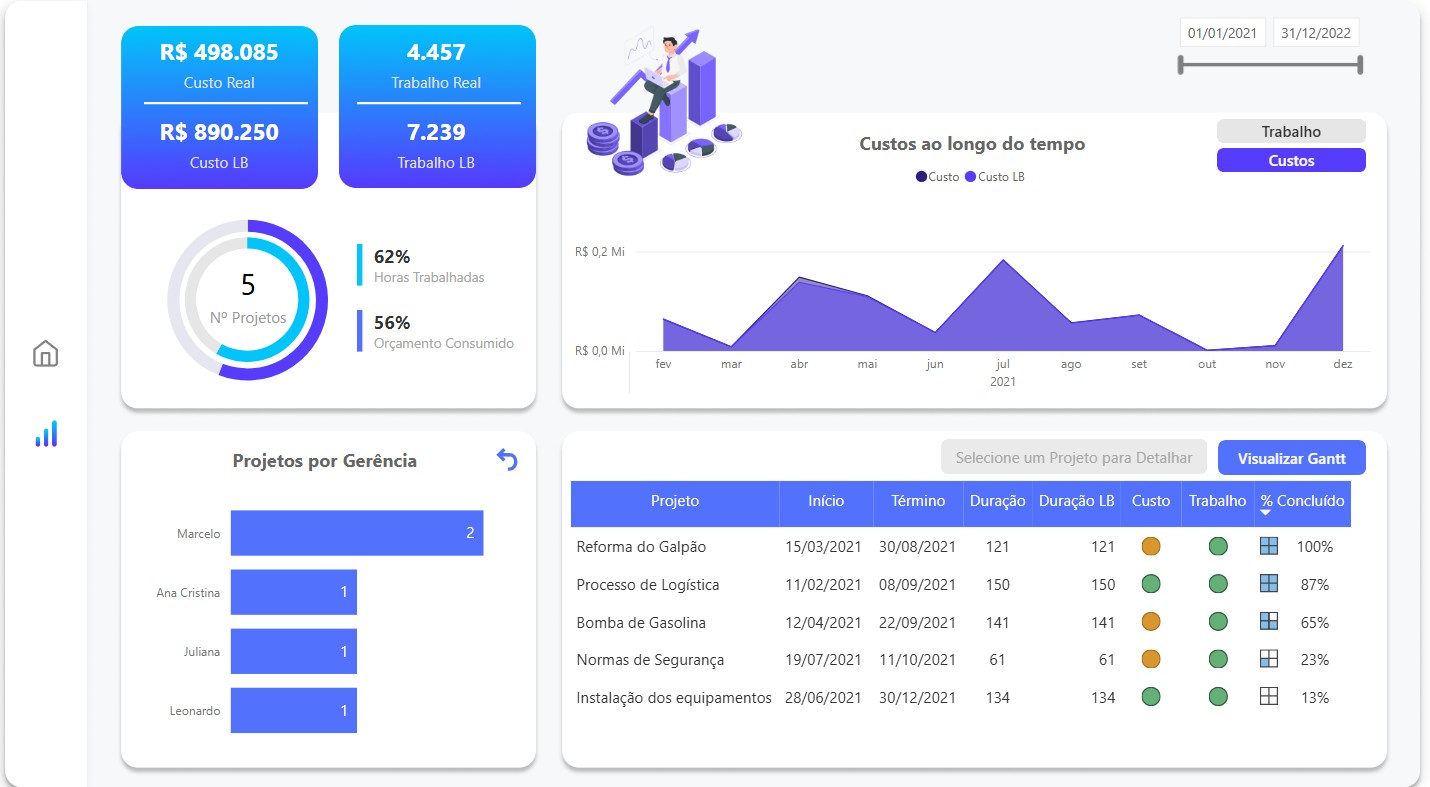
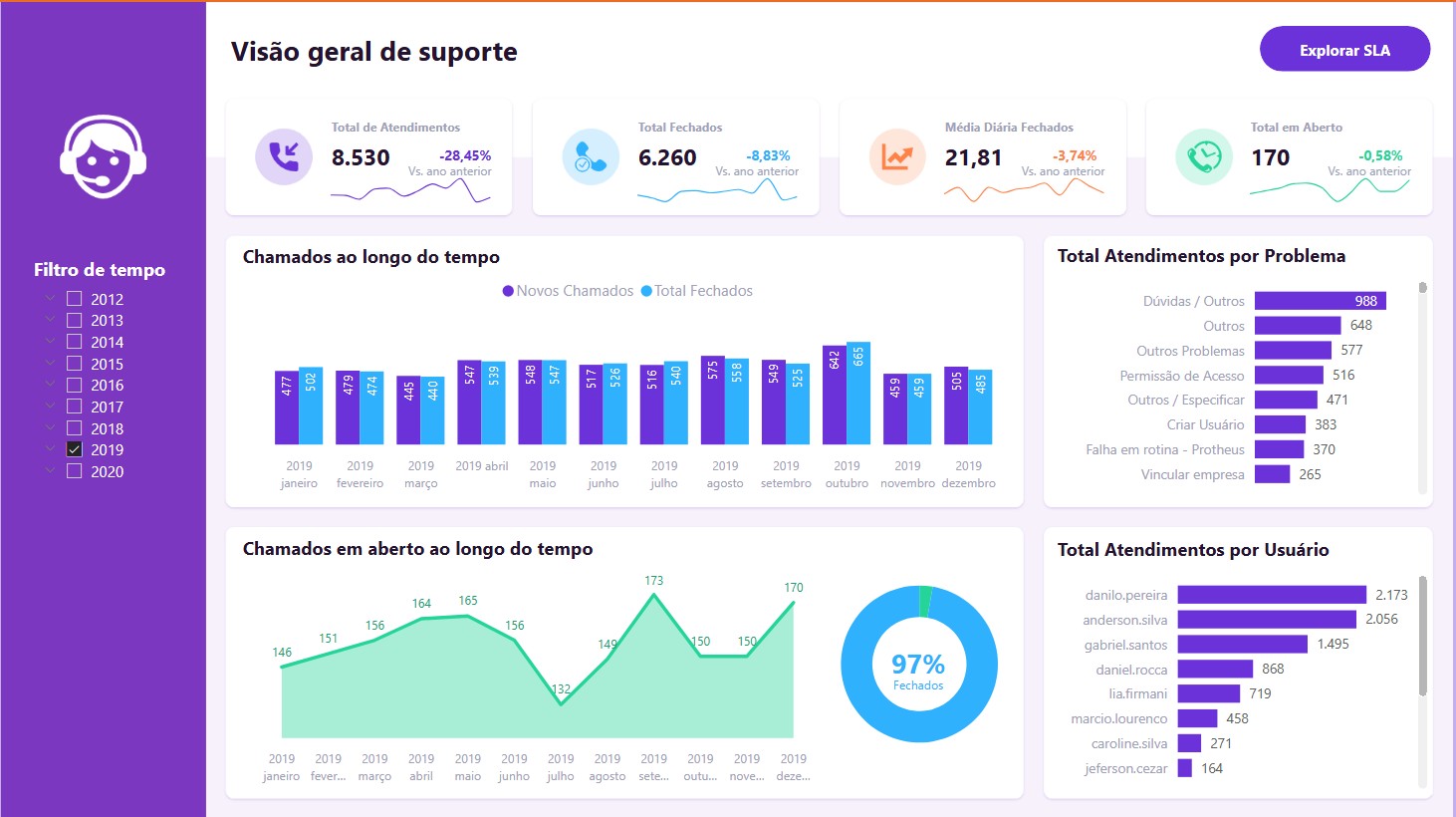
Olá! Sou Sarah Nascimento, especialista em Analytics Engineering, Arquitetura de Dados e Administração de Bancos de Dados (DBA).
Tenho forte atuação técnica conectando as necessidades do negócio com a infraestrutura de dados. Minha vivência abrange desde o desenho de arquiteturas escaláveis (Data Warehouses/Lakehouses) até a modelagem dimensional impecável para suporte analítico.
Sou apaixonada por performance tuning, refatoração de consultas críticas, otimização estrutural de bancos relacionais/analíticos e governança, garantindo que o dado chegue rápido, limpo e com alto nível de confiabilidade ao usuário final.
Stack Tecnológico & Skills
SQL Server & Tuning Avançado
Modelagem de Dados
Analytics Engineering
GCP & BigQuery
Arquitetura Cloud (AWS)
Python Data Stack
Databricks & Delta Lake
Modelos Semânticos (BI)
Formação Acadêmica
- Inteligência Artificial (Graduação) – Universidade Cruzeiro do Sul (2022 - 2024)
- Física (Licenciatura) – Centro Universitário Una (2024 - 2027)
- Eletroeletrônica (Pós-médio) – CEFET-MG (2018 - 2021)
- Mecatrônica (Técnico) – SENAI (2017 - 2018)
Analytics Engineering
Design e implementação de fluxos de transformação de dados e modelagem dimensional, focando na entrega de valor e qualidade da informação.
DBA & Database Tuning
Otimização de performance extrema, administração de bancos relacionais/analíticos, estruturação de índices e refatoração de queries críticas.
Arquitetura de Dados
Desenho de infraestruturas escaláveis em Cloud (AWS/GCP), definição de Data Warehouses, Lakehouses e padrões sólidos de governança.
Data Analytics & Modelos BI
Criação de modelos semânticos robustos e dashboards visuais interativos para traduzir estruturas complexas em decisões de negócio estratégicas.